
Wie künstliche Intelligenz Objekte erkennt und in die Zukunft schaut
Um welches Fahrzeug handelt es sich, wo wird es voraussichtlich hinfahren und wann die Spur wechseln: Künstliche Intelligenz durchforstet in Bruchteilen einer Sekunde gigantische Datenmengen, schafft neue Erkenntnisse über den Verkehr und legt die Basis für Mehrwertdienste.
Ein Auto, das intelligent ist, weiß, auf welcher Spur es fahren sollte, damit der Verkehr nicht ins Stocken gerät. Es beschleunigt oder fährt langsamer, wenn es sinnvoll ist. Es kann sogar erkennen, dass es bei einer ähnlichen Konstellation an einer Kreuzung sehr häufig zu einem Unfall kommt und macht Vorschläge, was zu tun ist. Christoph Schöller, Wissenschaftler bei fortiss, schaut mit Hilfe von künstlicher Intelligenz ein kleines Stück in die Zukunft. Er nennt das „Bewegungsprädiktion“. Sein Ziel ist klar: „Sicher Kollisionen vorhersagen zu können ist so etwas wie der heilige Gral unserer Forschung.“
„Sicher Kollisionen vorhersagen zu können ist so etwas wie der heilige Gral unserer Forschung“, sagt Christoph Schöller von fortiss.

„Sicher Kollisionen vorhersagen zu können ist so etwas wie der heilige Gral unserer Forschung“, sagt Christoph Schöller von fortiss.
KI: Eigenständig Probleme lösen
So weit ist es also noch nicht. Damit Schöller überhaupt erst seine Forschungen vorantreiben und bis Ende des Jahres seine Doktorarbeit abschließen kann, war und ist eine Menge Vorarbeit nötig. Erst Objekte erkennen (I.), dann Daten fusionieren (II.) und zuletzt Bewegungen vorhersagen (III.): Das sind die drei Schritte, an denen Wissenschaftler von Konsortialführer TU München und Partner wie fortiss im Projekt Providentia++ seit viereinhalb Jahren forschen. Überall, wo das System lernt sowie eigenständig Antworten findet und Probleme löst, trägt künstliche Intelligenz (KI) mit dazu bei, nicht nur einen präzisen digitalen Zwilling des Verkehrs zu entwickeln, sondern auch die Basis für Apps zu schaffen, die konkrete Empfehlungen geben können.
1. Neuronale Netze für die Erkennung von Objekten
Um Bewegungen im Verkehr vorhersagen zu können, ist es nötig, Fahrzeuge digital zu erfassen und in einem digitalen Zwilling des Verkehrs darzustellen. Dafür blicken Sensoren wie Kameras, Radare und Lidare auf den Verkehr.
Gerade die Detektionen der Fahrzeuge haben es in sich: Um sie möglichst sicher bestimmen zu können, benötigen neuronale Netze so genannte annotierte Daten. Das sind Rohdaten, bei denen die Positionen der Fahrzeuge bereits manuell nachjustiert und optimiert wurden. Da dieser Prozess sehr viel Zeit in Anspruch nimmt, weicht man auf vorhandene öffentliche Datensätze aus, die bereits über sehr genaue Annotationen verfügen. Und davon möglichst viele: „Man kann nie genug von annotierten Daten haben, kommt schlecht ran und der Aufwand, sie selbst zu erzeugen, ist sehr hoch“, sagt der Wissenschaftler der TU München Walter Zimmer, der für die Erkennung von Verkehrsteilnehmern bestehende Datensätze verwendet (MS COCO und Visdrone). Doch haben sie ihre individuellen Nachteile: MS COCO basiert auf 118.000 annotierten Bildern, erfasst aber keine Vans. Visdrone bietet mehr als doppelt so viele annotierte Bilder (265.000), die noch dazu von einer Drohne aus der Luft aufgenommen wurden. „Das kommt uns entgegen, da wir ja mit unseren Sensoren auf den Schilderbrücken auch von oben auf die Fahrzeuge herabschauen“, so Zimmer. Der Nachteil: Manchmal bekommt das neuronale Netz die Differenzierung zwischen Van und Pkw nicht hin und springt zwischen diesen Klassen hin und her. Deshalb hat Informatiker Zimmer ein eigenes Programm entwickelt, das Daten auf der Providentia++-Teststrecke semiautonom annotiert. „Das Programm automatisiert vieles“, sagt Zimmer, der dessen erste Version bereits 2019 auf der Intelligent Vehicles Conference in Paris veröffentlicht hat. Auch für die 3D-Detektion lässt sich das Programm nutzen, auf dessen Basis nun der Datensatz Provid-21 entsteht.

„Man kann nie genug von annotierten Daten haben, kommt schlecht ran und der Aufwand, sie selbst zu erzeugen, ist sehr hoch“, sagt der Wissenschaftler der TU München Walter Zimmer.
Zusätzlich kommt bei der 3D-Detektion der KITTI-Datensatz zum Einsatz, „ein vergleichsweise kleiner Datensatz, auf dem man schneller trainieren kann“ (Zimmer). Weiterhin greifen die Wissenschaftler auf den nuScenes- und Waymo-Datensatz zurück, die eine größere Vielfalt an Objekten erfassen.
2. Klassische Algorithmen in der Datenfusion
In der Fusion werden die „Erkenntnisse“ der Detektionen in einer High-Level-Fusion zusammengebracht. Dabei kommen „klassische Algorithmen“ zum Einsatz, die nicht aus Daten lernen, allerdings die Informationen aus der KI-Bilderkennung nutzen können. Vorteil: Sie generalisieren neue und unbekannte Situationen besser und deren Funktion ist im Gegensatz zu neuronalen Netzen beweisbar. Nach Ansicht von Christoph Schöller handelt es sich dabei aber nicht um künstliche Intelligenz. „Es werden statistische Methoden verwendet, um Daten zu fusionieren“, erläutert der fortiss-Wissenschaftler, „das System lernt nicht datengetrieben, kann also aus der Historie keine Schlüsse ziehen“. Siehe auch: Viele Sensoren, ein Zwilling: Wie geht das?
3. Neuronale Netze in der Vorhersage von Bewegungen
Umso wichtiger wird die künstliche Intelligenz, wenn Bewegungen des Fahrzeugs vorhergesagt werden sollen, die so genannten Trajektorien. Um aus einer Vielzahl an Daten wie beispielsweise auf der A9 die wichtigsten Auffälligkeiten herauszuziehen, hilft eine typische Eigenschaft der neuronalen Netze: „Trainiert man ein neuronales Netz auf fünf Trajektorien, merkt es sich, wie sich jedes Fahrzeug danach bewegt“, sagt Schöller, „wenn allerdings mehr dazukommen, wird das immer schwieriger. Sobald sich das Netz die riesigen Datenmengen nicht mehr merken kann, ist es gewissermaßen gezwungen, generalisierbare Muster zu erkennen.“ Aus der Not des neuronalen Netzes wird eine Tugend für Christoph Schöller. Denn mit Hilfe dieser generalisierten Muster lässt sich ableiten, auf welchen „Trajektorien“ sich Fahrzeuge sehr wahrscheinlich bewegen werden. „Wir extrapolieren in die Zukunft“, sagt Schöller, der sich aktuell schon auf eine besondere Herausforderung vorbereitet – auf den Verkehr an den Kreuzungen, die in der Testfelderweiterung mit aufwendiger Sensorik bestückt werden. „Auf der Autobahn sind die Bewegungen recht uniform, die Geschwindigkeiten weitgehend konstant und Spurwechsel nachvollziehbar. Die Manöver an einer Kreuzung mit Radfahrern, Fußgängern und mehreren Abbiegeoptionen ist weitaus komplexer“, so Schöller, der bereits ein Modell dafür entwickelt hat, das die Bewegungen aller Verkehrsteilnehmer („Agenten“) und das Straßenlayout in die Prädiktion einbezieht. Ein großes Plus für dieses Modell bietet die externe Infrastruktur in Providentia++: Denn durch die Vogelperspektive blickt es weiter als bisher, erkennt Fahrzeuge, die durch andere verdeckt sind und ermöglicht somit eine zuverlässigere Vorhersage.
Mehrwertdienste sind nur mit KI machbar
Als letzter Schritt fehlt jetzt eigentlich nur noch eine App, die die genannten Services an vernetzte Fahrzeuge weitergibt. Die Voraussetzungen sind gut: „Schon heute bekommen Testfahrzeuge von Valeo und Elektrobit die digitalen Zwillinge in Quasi-Echtzeit von 40 ms an Bord“, erläutert Wissenschaftler Zimmer. Eine spezielle Software wurde dafür programmiert, die nun „nur“ noch zu einer eigenen App weiterentwickelt werden muss. Der Vorteil einer solchen App liegt auch hier wieder in der externen Infrastruktur: Denn für die digitalen Zwillinge steht weitaus mehr Rechenleistung zur Verfügung. Die komplexen Berechnungen der Trajektorien sind längst gemacht, bevor sie an Bord eines Fahrzeugs übertragen werden.
Weitere Informationen
AI Self-Driving Cars Divulgement: Practical Advances in Artificial Intelligence and Machine Learning by Lance Eliot, 7-2020
FloMo: Tractable Motion Prediction with Normalizing Flows, Christoph Schöller und Alois Knoll
What the Constant Velocity Model Can Teach Us About Pedestrian Motion Prediction, Christoph Schöller, Vincent Aravantinos, Florian Lay, Alois Knoll
YOLOv4: Optimal Speed and Accuracy of Object Detection, Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao
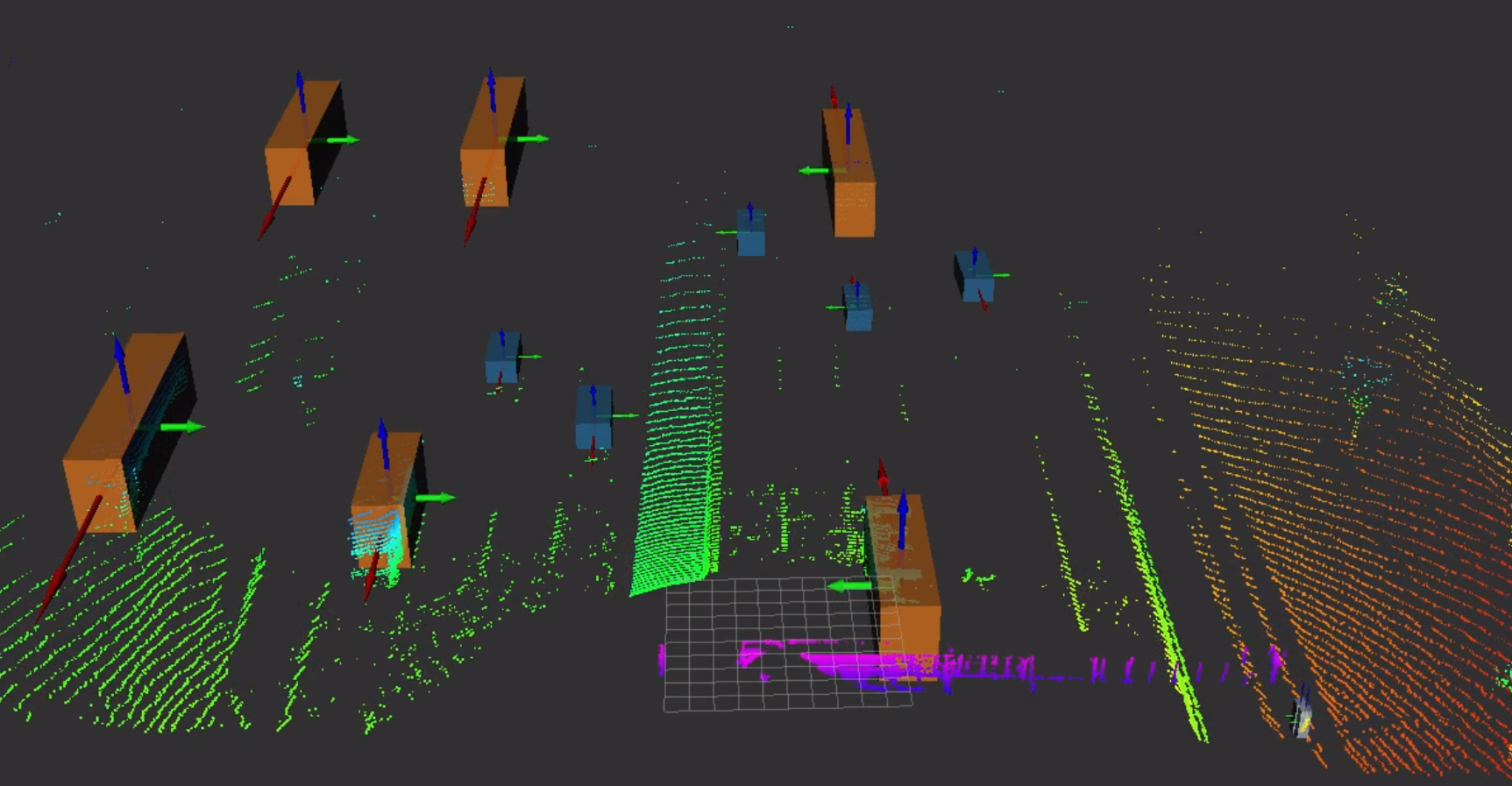

(1.) 3D Objektdetektion in LiDAR Daten (blau: PKW, orange: LKWs, grün: Fahrbahn, pink: Schilderbrücke)
(2.) proAnno-Labeling-Tool, mit dem der Providentia++ 3D Datensatz PROVID-21 erstellt wird.
(3.) 3D BAT: Bounding-Box-Annotation-Toolbox für das Labeling von LiDAR-Punktwolken in 3D. Quelle:https://ieeexplore.ieee.org/abstract/document/8814071
WEITERE AKTUELLE THEMEN

Cognition Factory: Kameradaten auswerten und visualisieren
Seit Beginn der Forschungen in Providentia++ am digitalen Zwilling ist KI-Spezialist Cognition Factory GmbH auf die Verarbeitung von Kameradaten fokussiert. Geschäftsführer Dr. Claus Lenz mit seinem Resümee.

Digitaler Echtzeitzwilling des Verkehrs: Serienreif und rund um die Uhr einsetzbar
Konsortialführer TU München hat das Forschungsprojekt für automatisiertes und autonomes Fahren Providentia++ entscheidend vorangebracht. TUM-Projektleiter Venkatnarayanan Lakshminarashiman zieht Bilanz.

Elektrobit: Test Lab auf stationäre Daten münzen
Elektrobit legt nicht zuletzt durch die Fortschritte in Providentia++ die Basis für Big-Data-Auswertungen von Verkehrsdaten. Simon Tiedemann von Elektrobit über die Entwicklungen im Rahmen von P++.