
Plausibility checks of sensors: Particularly efficient in networks

Intel has developed a plausibility check to find out whether roadside infrastructure monitoring sensors are measuring the right thing. The more sensors are integrated in a network such as Providentia++, the easier it is to find errors. Intel researcher Dr. Florian Geißler on the art of identifying and excluding bad measurements.
Dr. Geißler, in order for connected driving to improve traffic performance, reliable infrastructure monitoring is required. What kind of problems or errors can infrastructure sensors experience?
There are many possibilities. It could be that the sensor has been imperceptibly rotated a bit, the lens is dirty, or the sensor has unusually high noise. And just like that, a sensor in the sensor network misses an object. Vehicles are off the road map, which is highly unlikely. Pedestrians are traveling faster than should actually be physically possible, and objects’ trajectories include jumps or zigzag lines. To find out whether a system’s results are plausible, we developed a model that calculates a so-called plausibility score for each detected object, a value between 0 (not plausible) and 1 (extremely plausible). The model can be used for all sensor networks – not only in connected and collaborative driving, but also in other fields where reliable coordination is required, such as industrial robotics.
How do you go about this?
The goal is to verify the perception of objects. The more sensors you have with an overlapping field of view, the more successful this becomes. In the case of a vehicle, not all images can be replicated, simply because the sensors are not designed to be redundant. So to check the plausibility of the perception, a second view of things can make sense. Apart from that, we are trying to replicate the intuition that characterizes a human being in traffic. We have already investigated this using radars in the KoRA9 research project. If, for example, a truck drives close to a guardrail, the radar may measure the reflections of the guardrail. However, the vehicle would then be outside the lane. Here, the system should be able to recognize that this is inconclusive even without a ground truth. But it’s also clear that our system becomes particularly efficient with many sensors.
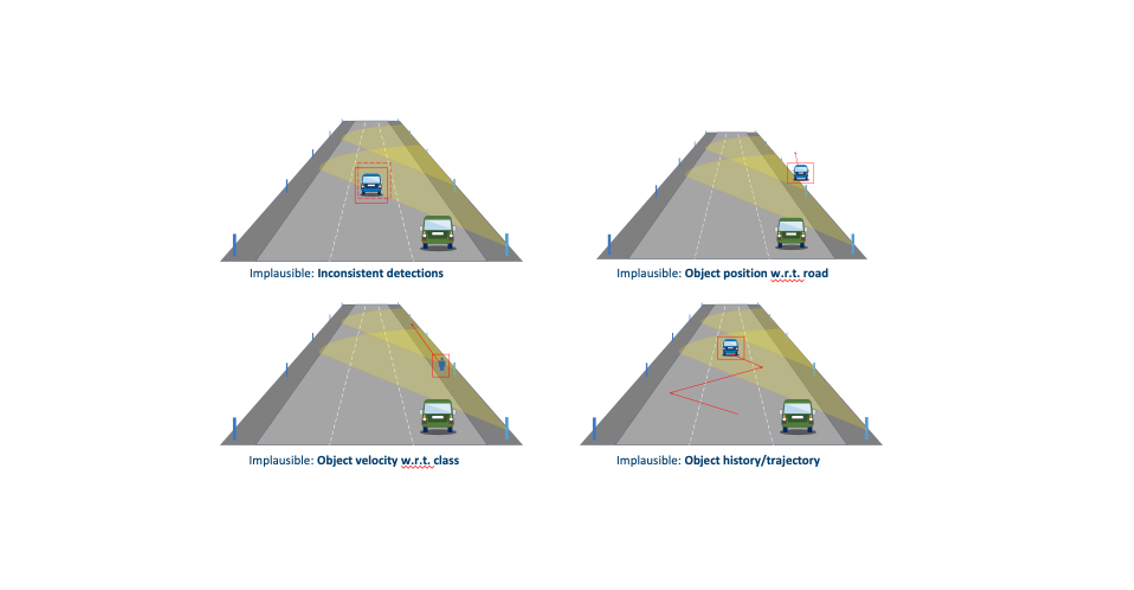
(I.) Typical detection faults
(II.) Plausibility score of objects
(III.) Plausibility signature
Where do you see particular advantages to your plausibility check?
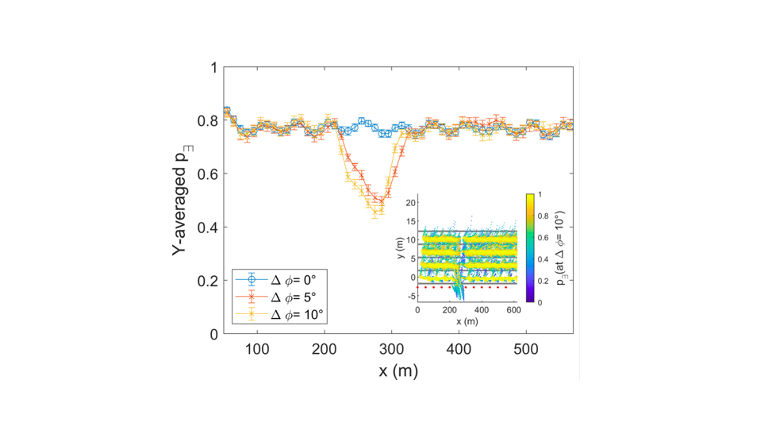
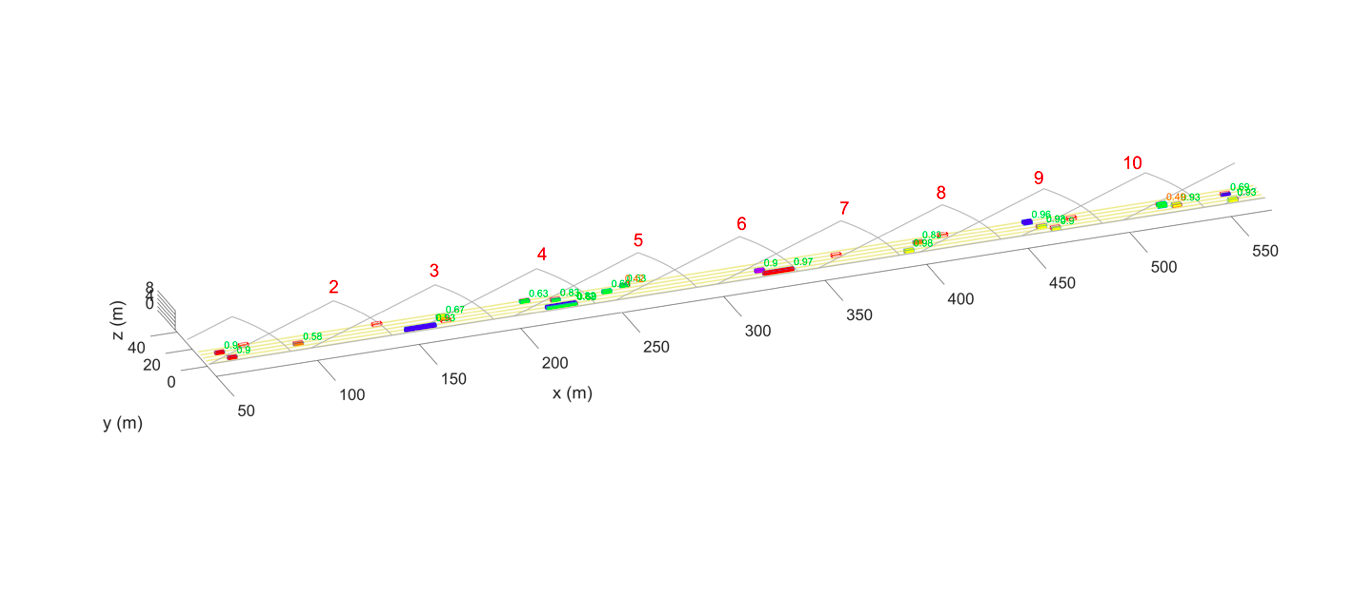
Because our plausibility score is based on infrastructure sensors as well as connected vehicle sensors, this expands the limited perspective of a single vehicle. In addition, we feed our plausibility module with three types of data: In the single check, individual sensors find errors (such as an unusual signal-to-noise ratio, movements outside the road boundaries, etc.). A cross check correlates the view of at least two sensors with the same field of view (do all the sensors detect an object?). And in model-based checks, not only are several sensors involved, but connections between the data are established (for example via complex trajectories, or regarding different properties of the same object such as speed and class). From this information, our system calculates a plausibility value (between 0 and 1) for each individual object traveling on the road. This plausibility check takes place in parallel with the data fusion (see also: Many sensors, one digital twin: How does it work?) and is part of the overall data fusion.
In a simulation, you analyzed three typical errors separately. What did you find?
In the first case, the sensor has turned slightly to the side, but the overall system knows nothing about this slight change in perspective. In the second case, sensors were configured incorrectly and noise signals were misinterpreted, and as a result too many vehicles were detected. In the third case, one sensor (out of two in use) does not detect all objects because the sensor lens is dirty. The plausibility signatures show which errors are involved in each case. In the case of the first error, the error rate of the affected sensor increases to more than 60 percent. In the case of the second, the error rates of the neighboring sensors of the faulty sensor increase, which is characteristic of configuration deficiencies. A characteristic picture also emerges with the third error. Here, it becomes particularly clear how important it is to consider as many sensors as possible in the monitoring sensor network, which is what we are doing in the Providentia++ research project. However, it is also clear that our model detects errors, but does not correct them. That is the task of the overall data fusion.
For more scientific information on plausibility checks, see the following publication:
A Plausibility-Based Fault Detection Method for High-Level Fusion Perception Systems
By Florian Geissler, Alexander Unnervik, and Michael Paulitsch
Information about the research project KoRA9 (in German)
Foto: iStock
FURTHER CURRENT TOPICS

Cognition Factory: Evaluate and visualize camera data
Since the beginning of research on the digital twin, AI specialist Cognition Factory GmbH has focused on processing camera data. In the meantime Dr. Claus Lenz has deployed a large-scale platform

Digital real-time twin of traffic: ready for series production
Expand the test track, deploy new sensors, decentralize software architecture, fuse sensor data for 24/7 operation of a real-time digital twin, and make data packets public: TU Munich has decisively advanced the Providentia++ research project.

Elektrobit: Coining Test Lab to stationary data
Elektrobit lays the foundation for Big Data evaluations of traffic data. Simon Tiedemann on the developments in P++.