Resilience for sensors and algorithms: 3 errors in focus

Machine learning solutions architect Dinu Purice from Providentia++ partner Cognition Factory is working on algorithms to make the digital twin as reliable as possible. What strategies can be used when software, computers, or sensors do not deliver optimal results?
Mr. Purice, as an AI expert, you are involved in making the Providentia++ system as reliable as possible. How do you go about this?
We basically have two overarching goals: A neural network should be trained on the basis of the best possible data, and it should become resistant to errors. This is not trivial, because the data sets with which the neural networks are trained do not yet come directly from the place where they will be applied. This means that our training data is mainly obtained from the vehicle perspective. So although we use data sets that can recognize cars, buses, and trucks, for example, as well as deal with vehicles that are partially obscured by another vehicle, the perspective of the training data is different from that at the scene. Our goal, however, is for the training data to include everything we see in real life.
Data set initiative: Building a data set to train neural networks
Why not just use the data from the Providentia++ project?
All the project partners are extremely interested in the data. In order to obtain a suitable data set for all partners, the data from the different sensors from Providentia++ must first be collected, merged, and labeled. This involves a great deal of effort, and not everything is relevant for every partner. Therefore, this must be carefully coordinated and the workload must be distributed. We are also currently working on having our own data available for training our neural networks. In addition, we will be able to include external influences and to validate our results. For example, in rainy or snowy conditions, comparing the results of the sensor data will make it possible to include lidars and radars rather than area scan cameras.
The test section is currently being enhanced. New lidars, 360-degree cameras, and event-based cameras will complement the existing sensor setup of area scan cameras and radars. What does this mean for you?
The challenge lies in bringing the data from the sensors together, because they are displayed differently depending on the sensor: for example as images or as point clouds. They also have different system latencies.
For us, having many different sensors also means that there are more misinterpretations of the data overall. For example, with 360-degree cameras, depending on the position, a car may be displayed in a highly distorted way. On the other hand, the large number of sensors gives us the chance to validate every result. This means that errors in the overall system can be filtered out. Overall, it makes our work somewhat easier. And we can thus improve the reliability and precision of the Providentia++ system.
For us, the extension of the test section is an ideal setup to test and improve our modular software platform. We want to use this to make it possible to connect new measuring points more or less via plug & play and thus be able to scale them as desired.
Data for training neural networks, resilience layers, and sensor networks: Strategies for dealing with the most common errors
What kinds of errors can occur?
It can happen that a vehicle is not seen; that it is not detected in the location where it is; that it is assigned to the wrong vehicle class; or that we correctly identify a vehicle, but a few seconds later it is displayed as a new vehicle.
These errors can have very different causes, which we divide into three categories:
- At the software level, the neural network misinterprets data. This often has to do with the training data not being good enough. We need new data sets, which is why we are supporting the Providentia++ data set initiative. Additionally, due to the large number of software modules involved, there is a lot of room for errors to occur due to programming (bugs) or the algorithms used.
- At the computer hardware level, bit flips can falsify the information, for example. We try to counteract this with so-called resilience layers: The layer called “Ranger” rejects certain values at defined positions, “Clipper” resets suspicious fields, and another layer is able to interpolate suspicious values with the help of neighboring values.
- At the sensor hardware level, data from individual sensors can be faulty, for example due to miscalibration or poor visibility conditions. In external infrastructure sensor networks such as Providentia++, other sensors can be used to validate the result and find errors.
Car2Infrastructure (C2I): 5G guarantees real-time exchange of data between infrastructure and vehicle
An important requirement for the Providentia++ system is that it must be real-time capable and run around the clock. What does that mean for you?
In everything we do, we have to make sure that updates are possible, that new software can be installed, and that the system can be maintained. If an error occurs, we must be able to trace it back and correct it without affecting the entire system. This is why we have created modules, or encapsulated software building blocks. If there are problems with this, we can see it by looking at our component landscape – the entire pipeline. In addition, our primary goal is to keep the volume of data exchanged between the sensors and vehicles as low as possible. This is the only way a connected vehicle can benefit ad hoc from external sensor technology. This requirement forces us to make compromises. For example, there are fewer processes and validation steps between the transfer of information to a vehicle in order to be able to transmit information to the vehicle in real time via 5G. Of course there are also other use cases where real-time capability is not necessarily the focus. What is clear is that it is not “just” a matter of assembling modules, but also of keeping an eye on the entire pipeline in order to select the algorithms that are best suited to the use case in question – and that enable the most error-free operation possible.
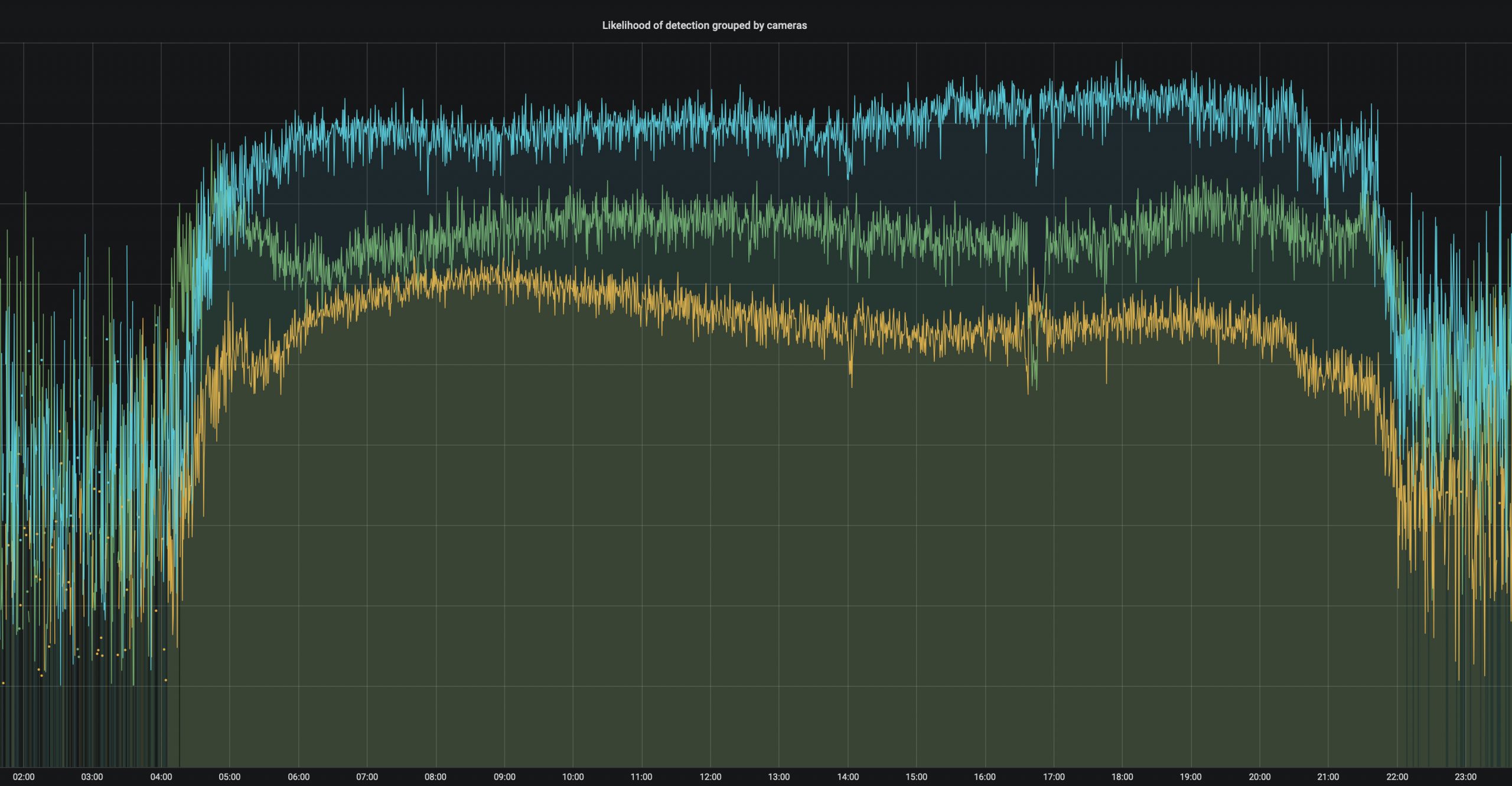
Graphic (above): The reliability of the cameras depends on their position and the time of day. At night, radars supplement the view.
FURTHER CURRENT TOPICS

Cognition Factory: Evaluate and visualize camera data
Since the beginning of research on the digital twin, AI specialist Cognition Factory GmbH has focused on processing camera data. In the meantime Dr. Claus Lenz has deployed a large-scale platform

Digital real-time twin of traffic: ready for series production
Expand the test track, deploy new sensors, decentralize software architecture, fuse sensor data for 24/7 operation of a real-time digital twin, and make data packets public: TU Munich has decisively advanced the Providentia++ research project.

Elektrobit: Coining Test Lab to stationary data
Elektrobit lays the foundation for Big Data evaluations of traffic data. Simon Tiedemann on the developments in P++.