Resilienz für Sensoren und Algorithmen: 3 Fehler im Fokus

Damit der digitale Zwilling möglichst zuverlässig wird, arbeitet der Solution Architekt für Maschinelles Lernen Dinu Purice von Providentia++-Partner Cognition Factory an Algorithmen, die ihn zuverlässiger machen. Welche Strategien helfen, wenn Software, Computer oder Sensoren zunächst keine optimalen Ergebnisse liefern?
Herr Purice, Sie beschäftigen sich als KI-Experte damit, das Providentia++-System möglichst zuverlässig zu machen. Wie gehen Sie vor?
Im Prinzip haben wir zwei übergeordnete Ziele: Zum einen sollte ein neuronales Netzwerk auf Basis von möglichst guten Daten trainiert werden und es soll widerstandsfähig werden gegen Fehler. Das ist nicht trivial. Denn die Datensätze, mit denen neuronale Netze trainiert werden, stammen aktuell noch nicht direkt von dem Ort, wo sie eingesetzt werden. Das heißt, dass unsere Trainingsdaten hauptsächlich aus der Fahrzeugperspektive gewonnen wurden. Wir verwenden also zwar Datensätze, die Pkws, Busse und Lkws erkennen und beispielsweise mit Fahrzeugen umgehen können, die durch ein anderes teilweise verdeckt werden. Doch ist der Blickwinkel der Trainingsdaten ein anderer als am Ort des Geschehens. Unser Ziel ist jedoch, alles, was wir im realen Leben sehen, auch in den Trainingsdaten wiederzufinden.
Dataset Initiative: Einen eignen Datensatz aufbauen, um neuronale Netze zu trainieren
Warum nutzen Sie nicht einfach die Daten aus dem Providentia++-Projekt?
Das Interesse an den Daten ist bei allen Projektpartnern sehr groß. Um einen passenden Datensatz für alle Partner zu erhalten, müssen die Daten der unterschiedlichen Sensoren aus Providentia++ erst einmal gesammelt, zusammengeführt und gelabelt werden. Das ist mit viel Aufwand verbunden und nicht alles ist für jeden Partner relevant. Deshalb muss man sich hier gut abstimmen und den Aufwand etwas verteilen. Wir arbeiten also gerade daran, eigene Daten auch für das Training unserer neuronalen Netze zur Verfügung zu haben. Zudem werden wir in der Lage sein, externe Einflüsse mit einzubeziehen und unsere Ergebnisse zu validieren. Es wird etwa möglich sein, im Regen oder Schnee eher Lidare und Radare einzubeziehen als Flächenkameras, indem wir die Ergebnisse der Sensordaten miteinander vergleichen.
Die Testrecke wird augenblicklich erweitert. Neue Lidare, 360-Grad-Kameras und Event-Based-Kameras ergänzen das bestehende Sensor-Setup aus Flächenkameras und Radaren. Was bedeutet das für Sie?
Die Herausforderung liegt darin, die Daten der Sensoren zusammenzubringen, denn sie werden jeweils unterschiedlich dargestellt, je nach Sensor etwa als Bilder oder als Punktwolken und haben unterschiedliche Systemlatenzen.
Viele unterschiedliche Sensoren: Das bedeutet für uns auch, dass insgesamt mehr Fehldeutungen und -interpretationen der Daten vorkommen. So kann etwa bei 360-Grad Kameras je nach Position ein Auto stark verzerrt dargestellt sein. Auf der anderen Seite haben wir durch die Vielzahl an Sensoren die Chance, jedes Ergebnis zu validieren. So können Fehler im Gesamtsystem herausgefiltert werden. Insgesamt erleichtert es uns die Arbeit ein Stück weit. Und wir können so die Zuverlässigkeit und Präzision des Providentia++-Systems verbessern.
Für uns ist die Teststreckenerweiterung ein ideales Set-up, um unsere modulare Software-Plattform zu testen und zu verbessern. Damit wollen wir es ermöglichen, neue Messpunkte quasi per Plug & Play anzuschließen und damit beliebig skalieren zu können.
Eigene Daten für das Training neuronaler Netze, Resiliance-Layer und Netzwerke aus Sensoren: Die Strategien gegen die häufigsten Fehler
Welche Fehler können auftreten?
Es kann passieren, dass ein Fahrzeug nicht gesehen wird, dass es nicht dort detektiert wird, wo es sich befindet, einer falschen Fahrzeugklasse zugeordnet wird oder dass wir beispielsweise ein Fahrzeug richtig identifizieren, es aber ein paar Sekunden später als ein neues Fahrzeug angezeigt wird.
Das kann ganz unterschiedliche Ursachen haben, die wir in drei Kategorien einteilen:
- Auf dem „Software Level“ interpretiert das neuronale Netzwerk Daten falsch. Das hat oft damit zu tun, dass die Trainingsdaten nicht gut genug sind. Wir benötigen neue Datensätze, weshalb wir die Dataset Initiative von Providentia++ unterstützen. Zusätzlich gibt es durch die Vielzahl an involvierten Software-Modulen viel Spielraum für Fehler, die aufgrund der Programmierung (Bugs) oder der verwendeten Algorithmen auftreten können.
- Auf dem „Computer Hardware Level“ können beispielsweise Bitflips die Information verfälschen. Mit so genannten Resiliance-Layern versuchen wir, dem entgegenzuwirken. Der „Ranger“ genannte Layer etwa verbietet bestimmte Werte an definierten Positionen, „Clipper“ setzt verdächtige Felder zurück und ein weiterer Layer ist in der Lage, verdächtige Werte mithilfe der Nachbarwerte zu interpolieren.
- Auf dem „Sensor Hardware Level“ können Daten einzelner Sensoren fehlerhaft sein, z.B. durch eine Fehlkalibrierung oder schlechte Sichtverhältnisse. Mithilfe anderer Sensoren lässt sich in externen Infrastrukturen wie Providentia++ in Sensornetzwerken das Ergebnis validieren und Fehler lassen sich finden.
Car2Infrastructure (C2I): 5G garantiert Austausch von Daten zwischen Infrastruktur und Fahrzeug in Echtzeit
Eine wichtige Anforderung für das Providentia++-System liegt darin, dass es echtzeitfähig sein und rund um die Uhr laufen muss. Was bedeutet das für Sie?
Bei allem, was wir tun, müssen wir darauf achten, dass Updates möglich sind, neue Software eingespielt werden und das System gewartet werden kann. Tritt ein Fehler auf, müssen wir ihn zurückverfolgen und beheben können, ohne dass das gesamte System beeinträchtigt wird. Aus diesem Grund haben wir Module geschaffen, gekapselte Software-Bausteine. Wenn es hiermit Probleme gibt, sehen wir das mit einem Blick auf unsere Komponentenlandschaft – die gesamte Pipeline. Hinzu kommt, dass wir das primäre Ziel haben, die Datenmenge, die zwischen den Sensoren und Fahrzeugen ausgetauscht wird, möglichst gering zu halten. Nur so kann ein vernetztes Fahrzeug adhoc von externer Sensorik profitieren. Diese Anforderung zwingt uns zu Kompromissen. So gibt es etwa weniger Prozesse und Validierungsschritte zwischen dem Transfer der Information zu einem Fahrzeug, um per 5G die Informationen in Echtzeit an das Fahrzeug übermitteln zu können. Natürlich gibt es auch andere Use Cases, in denen die Echtzeitfähig dann nicht unbedingt im Vordergrund steht. Klar ist: Hier geht es nicht „nur“ darum, Module zusammenzusetzen, sondern immer auch darum, die gesamte Pipeline im Blick zu haben, um die Algorithmen auszuwählen, die für den jeweiligen Use Case am besten passen – und die einen möglichst fehlerfreien Betrieb ermöglichen.
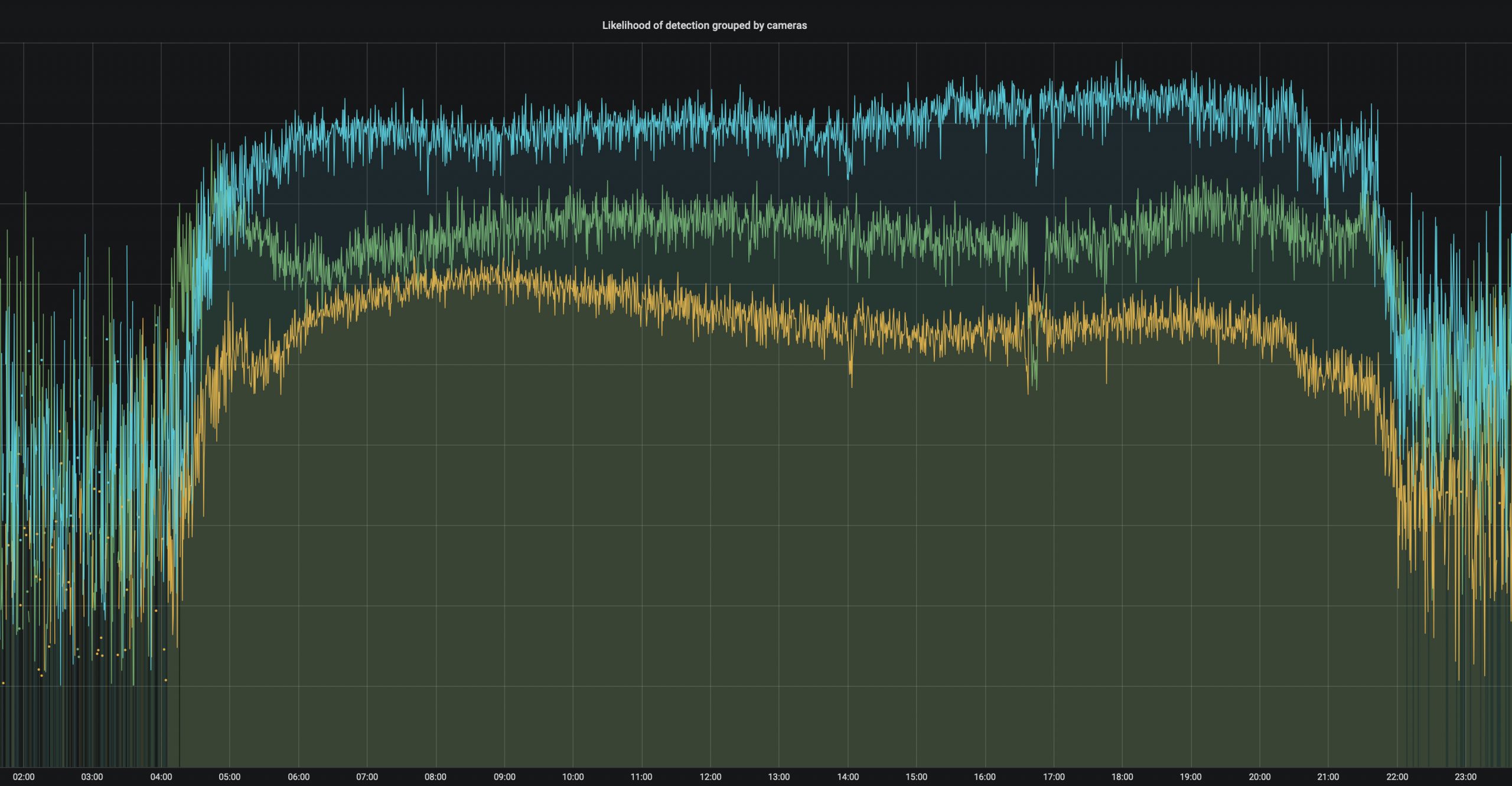
Grafik (oben): Die Zuverlässigkeit der Kameras hängt von deren Position und der Tageszeit ab. Nachts ergänzen Radare die Sicht.
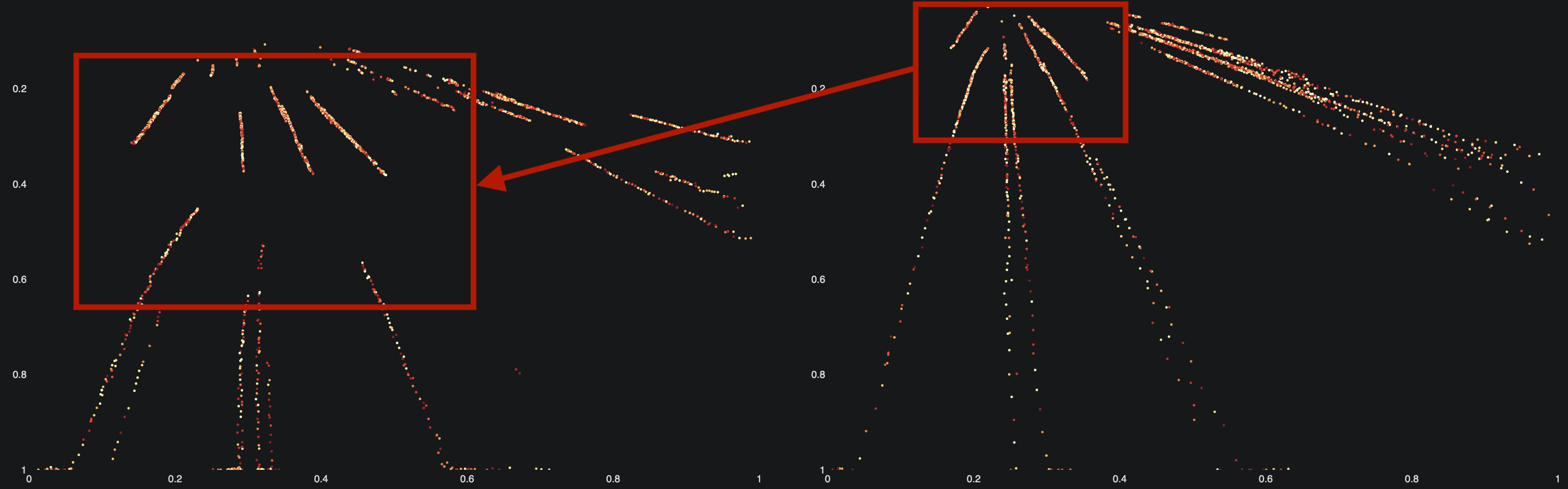
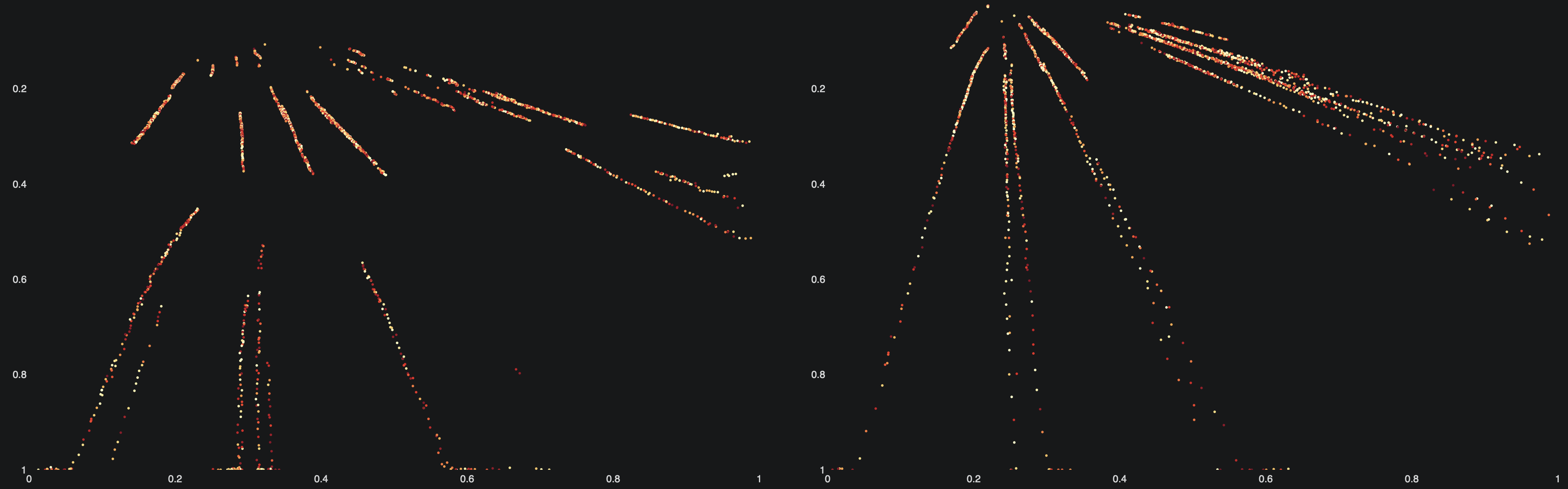
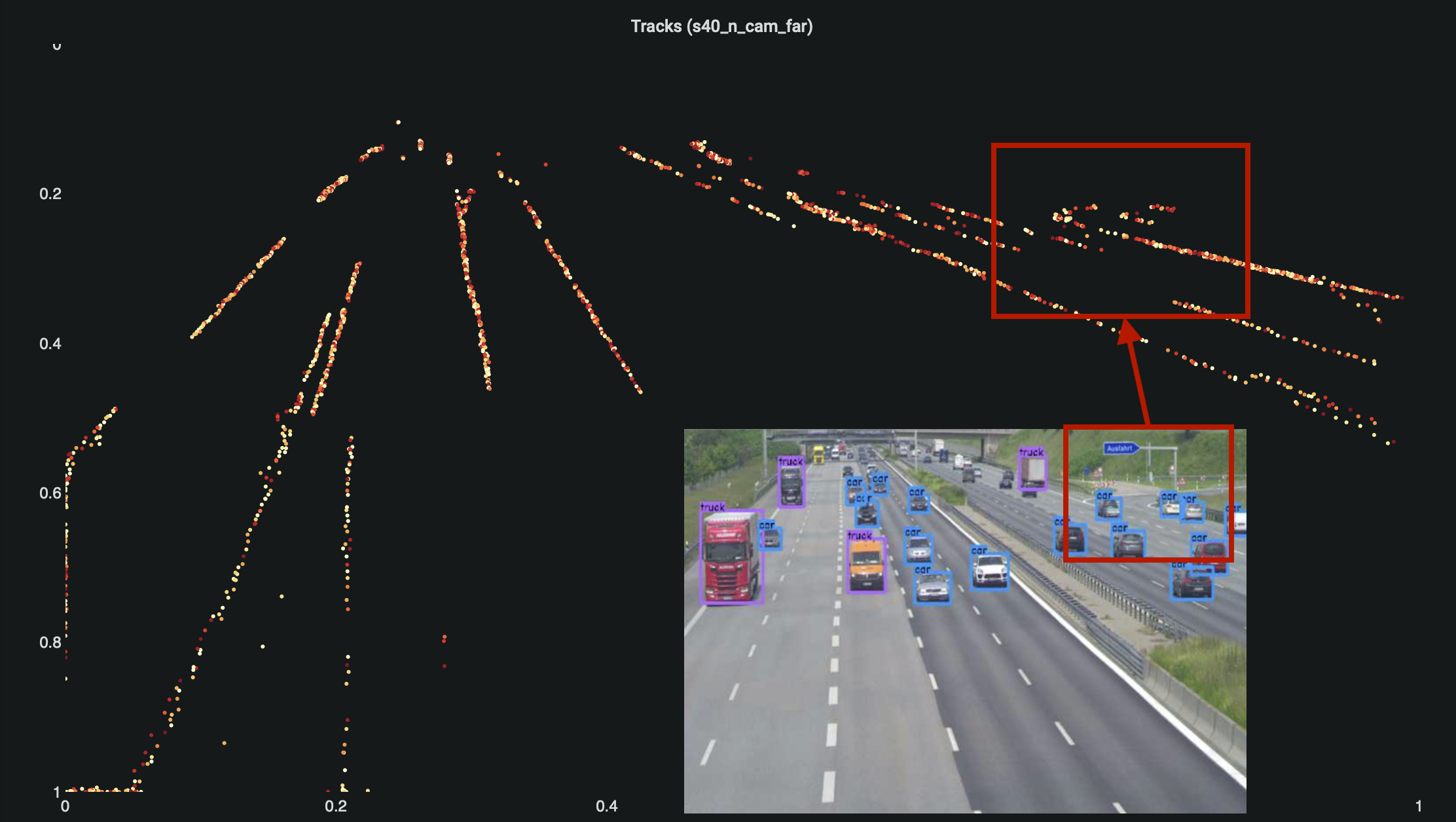
Die Punkte auf den Grafiken zeigen die Trajektorien der Fahrzeuge, also deren Bewegung über die Zeit hinweg.
WEITERE AKTUELLE THEMEN

Cognition Factory: Kameradaten auswerten und visualisieren
Seit Beginn der Forschungen in Providentia++ am digitalen Zwilling ist KI-Spezialist Cognition Factory GmbH auf die Verarbeitung von Kameradaten fokussiert. Geschäftsführer Dr. Claus Lenz mit seinem Resümee.

Digitaler Echtzeitzwilling des Verkehrs: Serienreif und rund um die Uhr einsetzbar
Konsortialführer TU München hat das Forschungsprojekt für automatisiertes und autonomes Fahren Providentia++ entscheidend vorangebracht. TUM-Projektleiter Venkatnarayanan Lakshminarashiman zieht Bilanz.

Elektrobit: Test Lab auf stationäre Daten münzen
Elektrobit legt nicht zuletzt durch die Fortschritte in Providentia++ die Basis für Big-Data-Auswertungen von Verkehrsdaten. Simon Tiedemann von Elektrobit über die Entwicklungen im Rahmen von P++.